Day 29 — EasyOCR dabblements
Today I paired with Andrew to try out EasyOCR since we thought that it could be useful in both chronicle (to extract text out of camera images) and camelot (to extract text out of image-based PDFs). Andrew suggested that we could use images from duetocovid19.com, another cool project that he has built!
Installing it with pip was easy, though it took a long time to download the 700MB PyTorch wheel from PyPI! Also, looks like PyTorch needs to be installed separately on Windows. After the installation, it took some more time to download the English language model:
>>> import easyocr
>>> reader = easyocr.Reader(['en'], gpu=False)
Using CPU. Note: This module is much faster with a GPU.
Downloading recognition model, please wait. This may take several minutes depending upon your network connection.
Progress: |███████████████| 100.0% Complete
It returned a very good output for the first image, probably because of the big letters with a standard font.
>>> result = reader.readtext('due-to-covid-19-1.jpg', detail=0)
>>> result
['PLEASE', 'BELIEVE', 'THESE', 'DAYS', 'WILL', 'PASS']
The output for the second image wasn't as good, maybe because it's one of those "changeable letter signs" where letters have a non-standard font, with a slightly uneven spacing between them.
>>> result = reader.readtext('due-to-covid-19-2.jpg', detail=0)
>>> result
['VENTURES',
'MNIVEHTURESCARHEIT LScu!',
'HIE',
'ARE',
'ALL',
'IN',
'THIS',
'TOGETIIER',
'STAV',
'MEALTIY',
'AND REMEMBER',
'SOCIAL',
'DISTANCING']
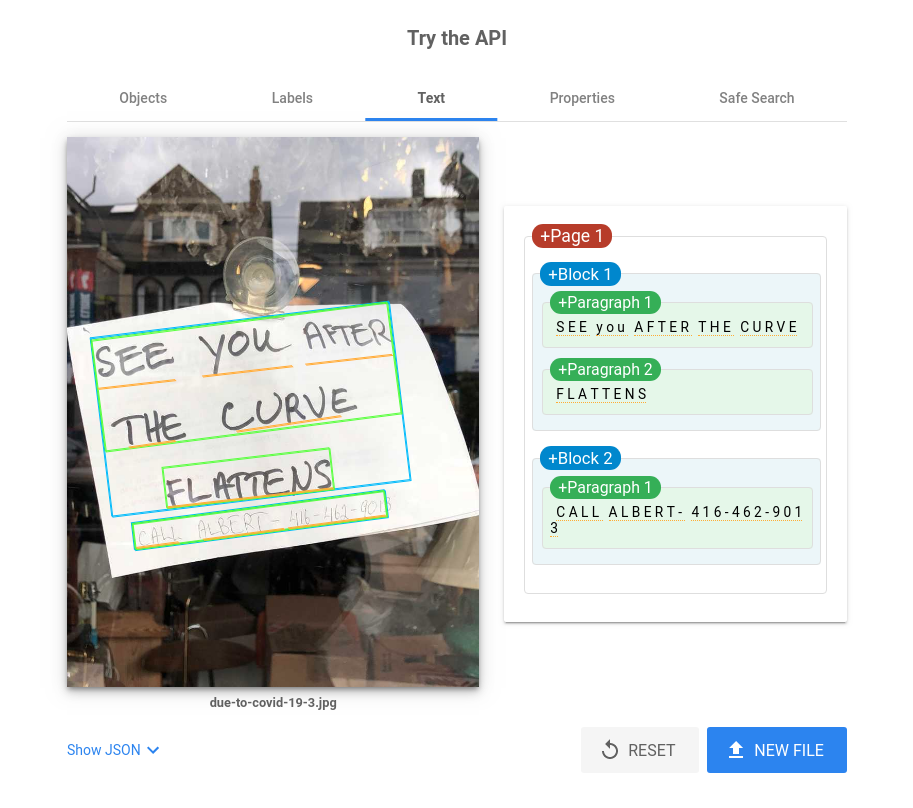
It returned the worst output for the third image even after we corrected the rotation, probably because the letters are handwritten.
>>> result = reader.readtext('due-to-covid-19-3.jpg', detail=0)
>>> result
['AFTER',
'you',
'SEE',
'cURVe',
'Tlle',
'FLAT7ENS',
'(@13',
'4[( = 4[(4',
'MeBCRT',
'CAL']
In contrast, here's the output from Google's Cloud Vision API. This is not a fair comparison as handwriting recognition is different than OCR (and also because GOOGL!). But it's interesting to note that Google's closed-source code solves both problems at once! Will they ever release it?
The output for the fourth image was good, probably because of a standard font, even though the layout is non-standard. It missed the space between "IS" and "GREAT" maybe because the letters aren't placed sufficiently far apart.
>>> result = reader.readtext('due-to-covid-19-4.jpg', detail=0)
>>> result
['WE ARE', 'PRAYING', 'FOR YOU.', 'GOD ISGREAT.']
The output for the fifth image was also good, because of a standard font and layout.
>>> result = reader.readtext('due-to-covid-19-5.jpg', detail=0)
>>> result
["wddcno's",
'gelati',
'THIS STORE IS CLOSED',
'UNTIL FURTHER NOTICE',
'Dear Gelato Friends,',
'We',
'are closing all our stores until further notice',
'We are doing this to protect the health of our staff',
'and our customers, and to help',
'the',
'NHS to deal with',
'this pandemic.',
'We hope to reopen as soon as it is safe to do SO.',
'your understanding',
'We',
'thank',
'for',
'you',
'and',
'your',
'support. Keep safe, keep healthy.',
"Oddono's Gelati Italiani"]
After these initial dabblements, I think it makes sense to use EasyOCR for adding OCR support to camelot, as PDFs usually have standard fonts.