An Open-Source Tool to Extract Tables from PDFs into CSVs
I have also published this post on Hacker Noon.
Borrowing the first three paragraphs from my previous blog post since they perfectly explain why extracting tables from PDFs is hard.
The PDF (Portable Document Format) was born out of The Camelot Project to create “a universal way to communicate documents across a wide variety of machine configurations, operating systems and communication networks”. Basically, the goal was to make documents viewable on any display and printable on any modern printer. PDF was built on top of PostScript (a page description language), which had already solved this "view and print anywhere" problem. PDF encapsulates the components required to create a "view and print anywhere" document. These include characters, fonts, graphics and images.
A PDF file defines instructions to place characters (and other components) at precise x,y coordinates relative to the bottom-left corner of the page. Words are simulated by placing some characters closer than others. Similarly, spaces are simulated by placing words relatively far apart. How are tables simulated then? You guessed it correctly — by placing words as they would appear in a spreadsheet.
The PDF format has no internal representation of a table structure, which makes it difficult to extract tables for analysis. Sadly, a lot of open data is stored in PDFs, which was not designed for tabular data in the first place!
Excalibur: Extract tables from PDFs into CSVs
Excalibur is a web interface to extract tabular data from PDFs, written in Python 3! It is powered by Camelot. You can check out fantastic documentation at Read the Docs and follow the development on GitHub.
Note: Excalibur only works with text-based PDFs and not scanned documents. (As Tabula explains, “If you can click and drag to select text in your table in a PDF viewer, then your PDF is text-based”.)
How to install Excalibur
After installing ghostscript (see install instructions), you can simply use pip to install Excalibur:
$ pip install excalibur-py
Note: You can also download executables for Windows and Linux from the releases page and run them directly!
How to use Excalibur
After installation with pip, you can initialize the metadata database using:
$ excalibur initdb
And then start the webserver using:
$ excalibur webserver
That’s it! Now you can go to http://localhost:5000 and start extracting tabular data from your PDFs.
-
Upload a PDF and enter the page numbers you want to extract tables from.
-
Go to each page and select the table by drawing a box around it. (You can choose to skip this step since Excalibur can automatically detect tables on its own. Click on “Autodetect tables” to see what Excalibur sees.)
-
Choose a flavor (Lattice or Stream) from “Advanced”.
a. Lattice: For tables formed with lines.
b. Stream: For tables formed with whitespaces.
-
Click on “View and download data” to see the extracted tables.
-
Select your favorite format (CSV/Excel/JSON/HTML) and click on “Download”!
Why use Excalibur?
- Extracting tables from PDFs is hard. A simple copy-and-paste from a PDF into an Excel doesn’t preserve table structure. Excalibur makes PDF table extraction very easy, by automatically detecting tables in PDFs and letting you save them into CSVs and Excel files.
- Excalibur uses Camelot under the hood, which gives you additional settings to tweak table extraction and get the best results. You can see how it performs better than other open-source tools and libraries in this comparison.
- You can save table extraction settings (like table areas) for a PDF once, and apply them on new PDFs to extract tables with similar structures.
- You get complete control over your data. All file storage and processing happens on your own local or remote machine.
- Excalibur can be configured with MySQL and Celery for parallel and distributed workloads. By default, sqlite and multiprocessing are used for sequential workloads.
A table detection upgrade
Camelot, the Python library that powers Excalibur, implements two methods to extract tables from two different types of table structures: Lattice, for tables formed with lines, and Stream, for tables formed with whitespaces. Lattice gave nice results from v0.1.0 since it was able to detect different tables on a single PDF page, in contrast to Stream which treated the whole page as a table.
But last week, Camelot v0.4.0 was released to fix that problem. #206 adds an implementation of the table detection algorithm described by Anssi Nurminen's master's thesis that is able to detect multiple Stream-type tables on a single PDF page (most of the time)! You can see the difference in the following images.
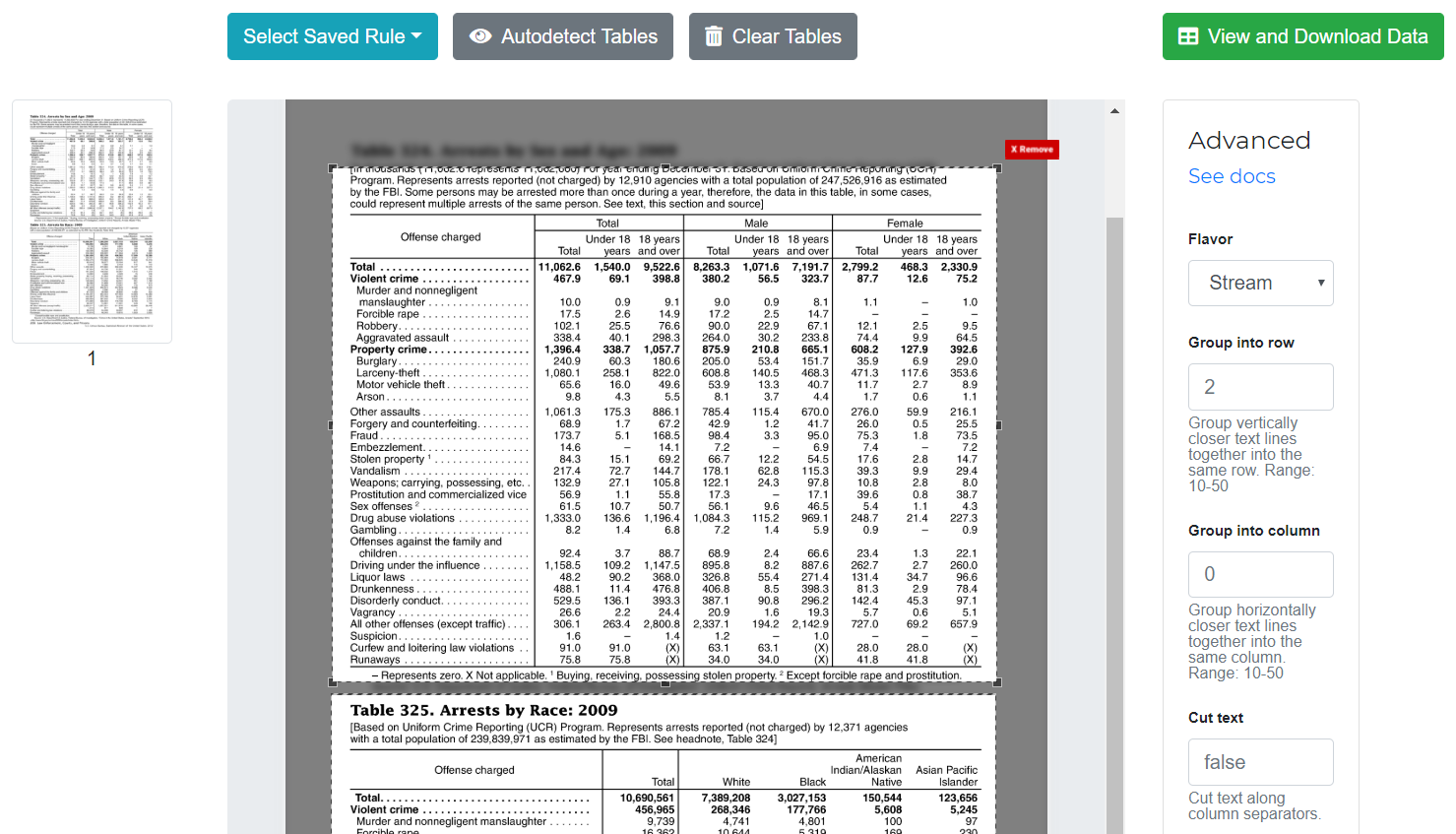
as compared to
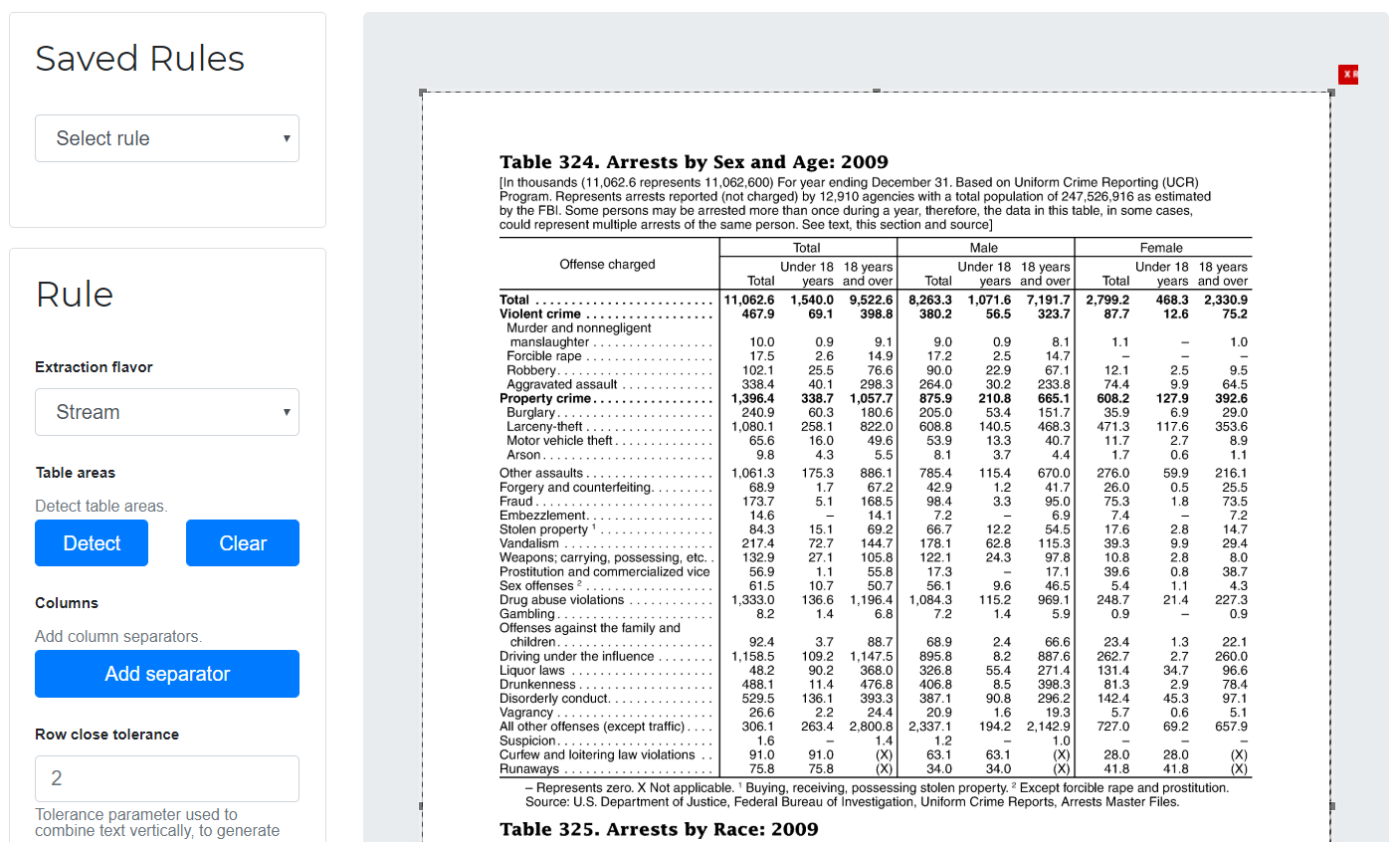
Voted #1 on Labworm
Excalibur was voted #1 on Labworm in the second week of November! Labworm is a platform that guides scientists to the best online resources for their research and helps mediate knowledge exchange by promoting open science.
Tweet of TheLabWorm/1063361003688247296
Why another PDF table extraction tool?
There are both open (Tabula, pdfplumber) and closed-source (Smallpdf, Docparser) tools that are widely used to extract data tables from PDFs. They either give a nice output or fail miserably. There is no in between. This is not helpful since everything in the real world, including PDF table extraction, is fuzzy.
Excalibur uses Camelot under the hood, which was created to offer users complete control over table extraction. If you can’t get your desired output with the default settings, you can tweak the "Advanced" settings and get the job done!
For a more detailed account of why Camelot was created, you should also check out "The longer read" section of my previous blog post. Use Ctrl + F.
The road ahead
Reiterating from "The longer read" section I talked about above, it was a pain to see open-source tools not give a nice table extraction output every time. And it was frustrating to see paywalls on closed-source tools. I think that paywalls should not block the way to open science. I believe that Camelot was a successful attempt by us, at SocialCops, to address the problem of extracting tables from text-based PDFs accurately. Excalibur has made it more easier for anyone to access Camelot's goodness with a nice web interface.
But there's still a lot of open data trapped inside images and image-based PDFs. And state of the art optical character recognition software is locked behind paywalls.
'At this time, proprietary OCR software drastically outperforms free and open source OCR software and as such could be worth a public agency's investment depending on the amount and type of OCR jobs the public agency is needing to perform.' — How to Open Data - Working with PDFs
So the next step is to make it easy for anyone to extract tables (or any other type of data for that matter) from images or image-based PDFs by adding OCR support to Camelot and Excalibur. If you would like to contribute your ideas towards this, do add your comments on #14. You can also check out the Contributor's Guide for guidelines around contributing code, documentation or tests, reporting issues and proposing enhancements.
If Excalibur has helped you extract tables from PDFs, please consider supporting its development by becoming a backer or a sponsor on OpenCollective!
Also, stop publishing open data as PDFs and keep looking up! :)
Thanks to Christine Garcia for providing feedback and suggesting edits.