Airflow, Meta Data Engineering, and a Data Platform for the World’s Largest Democracy
I originally wrote this post for the SocialCops engineering blog, and then published it on Hacker Noon.
In our last post on Apache Airflow, we mentioned how it has taken the data engineering ecosystem by storm. We also talked about how we’ve been using it to move data across our internal systems and explained the steps we took to create an internal workflow. The ETL workflow (e)xtracted PDFs from a website, (t)ransformed them into CSVs and (l)oaded the CSVs into a store. We also touched briefly on the breadth of ETL use cases you can solve for, using the Airflow platform.
In this post, we will talk about how one of Airflow’s principles, of being ‘Dynamic’, offers configuration-as-code as a powerful construct to automate workflow generation. We’ll also talk about how that helped us use Airflow to power DISHA, a national data platform where Indian MPs and MLAs monitor the progress of 42 national level schemes. In the end, we will discuss briefly some of our reflections from the project on today’s public data technology.
Why Airflow?
To recap from the previous post, Airflow is a workflow management platform created by Maxime Beauchemin at Airbnb. We have been using Airflow to set up batching data workflows in production for more than a year, during which we have found the following points, some of which are also its core principles, to be very useful.
- Dynamic: A workflow can be defined as a Directed Acyclic Graph (DAG) in a Python file (the DAG file), making dynamic generation of complex workflows possible.
-
Extensible: There are a lot of operators right out of the box! An operator is a building block for your workflow and each one performs a certain function. For example, the PythonOperator lets you define the logic that runs inside each of the tasks in your workflow, using Python!
-
Scalable: The tasks in your workflow can be executed parallely by multiple Celery workers, using the CeleryExecutor.
-
Open Source: The project is under incubation at the Apache Software Foundation and being actively maintained. It also has an active Gitter room.
Furthermore, Airflow comes with a web interface that gives you all the context you need about your workflow’s execution, from each task’s state (running, success, failed, etc.) to logs that the task generated!
The problem with static code
Here at SocialCops, we’ve observed a recurring use case of extracting data from various systems using web services, as a component of our ETL workflows. One of the ways to go forward with this task is to write Python code, which can be used with the PythonOperator to integrate the data into a workflow. Let’s look at a very rudimentary DAG file that illustrates this.
As you can observe, the PythonOperator can be instantiated by specifying the name of the function containing your Python code using the python_callable keyword argument. Multiple instantiated operators can then be linked using Airflow API’s set_downstream and set_upstream methods.
In the DAG file above, the extract function makes a GET request to httpbin.org, with a query parameter. Web services can vary in their request limit (if they support multiple requests at the same time), query parameters, response format and so on. Since writing custom Python code for each web service would be a nightmare for anyone maintaining the code, we decided to build a Python library (we call it Magneton, since it is a magnet for data), which takes in the JSON configuration describing a particular web service as input and fetches the data using a set of pre-defined queries. But that solved only half of our problem.
In our last post and in the example DAG file above, we could link operators together by writing static calls to the set_downstream and set_upstream methods since the workflows were pretty basic. But imagine a DAG file’s readability with 1,000 operators defined in it. You would have to be a savant to infer the relationships between operators. Moreover, everyone in your team (including people who don’t work with Python as their primary language) wouldn’t have the know-how to write a DAG file, and writing them manually would be repetitive and inefficient.
Meta data engineering
In his talk “Advance Data Engineering Patterns with Apache Airflow“, Maxime Beauchemin, the author of Airflow, explains how data engineers should find common patterns (ways to build workflows dynamically) in their work and build frameworks and services around them. He gives some examples of such patterns, one of which is AutoDAG. It is an Airflow plugin that Airbnb developed internally to automate DAG creation, allowing the users who just need to run a scheduled SQL query (and don’t want to go author a workflow) to create the query on the web interface itself.
Finding patterns involves identifying the building blocks of a workflow and chaining them based on a static configuration. Look at the DAG file that we showed in the section above and try to identify the building blocks. It has just three components, which can be modeled into a YAML configuration.
This is a very basic example. For a more detailed one, you should check out how Pachyderm and Digdag have modeled their workflow specifications, which they use to dynamically generate workflows.
This makes it easy for us to now write a single DAG file that can take in a bunch of these YAML configurations and build DAGs dynamically, by linking operators which have the same identifiers (in this example, we have used a number, 1, for the sake of simplicity). Moreover, anyone in your team who wants to create a workflow can just write a YAML, which makes it easy for a human to define a configuration that is machine-readable. Once you’ve figured out a way to create DAGs based on configurations, you can build a interface to let users build a DAG without writing configurations, making it easy for anyone looking to create a workflow!
For DISHA, we needed to (E)xtract scheme data from source systems via web services and then follow that with the T and L. At an atomic level, our workflows could be broken down into:
-
a PythonOperator to (E)xtract data from the source system, by using Magneton (the Python library we had developed).
-
a BashOperator to run R or Python-based (T)ransformations on the extracted data, like cleaning, reshaping, and standardizing geographies across data sets.
-
a PythonOperator to (L)oad the transformed data into our data warehouse, on which Visualize can run analytical queries.
-
Additionally, we added Slack and email alerts using the PythonOperator.
Identifying this pattern let us automate DAG creation. Using a web interface, anyone could now add the configuration needed for the three basic tasks outlined above. This helped us to distribute the work of setting up workflows within our small team, most of whom were comfortable only in R. Soon, everyone was writing R scripts and building intricate workflows, like the one below.
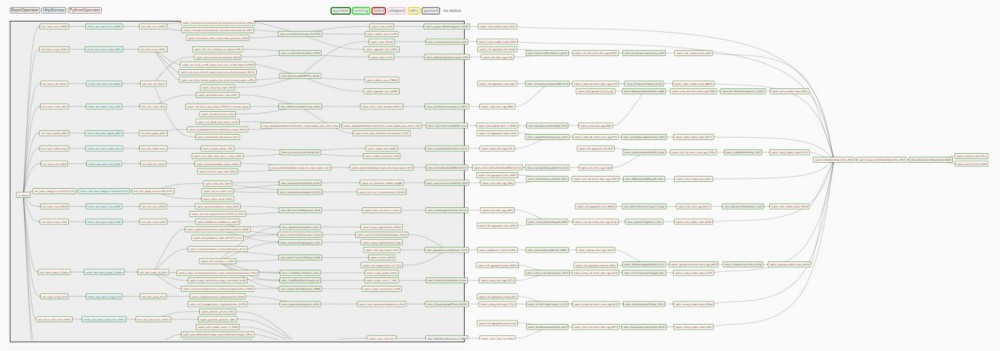
The Airflow web interface lets the project stakeholders manage complex workflows (like the one shown above) with ease, since they can check the workflow’s state and pinpoint the exact step where something failed, look at the logs for the failed task, resolve the issue and then resume the workflow by retrying the failed task. Making tasks idempotent is a good practice to deal with retries. (Note: retries can be automated within Airflow too.)
An overview on DISHA
‘DISHA is a crucial step towards good governance through which we will be able to monitor everything centrally. It will enable us to effectively monitor every village of the country.’ — Narendra Modi, Prime Minister of India
The District Development Coordination and Monitoring Committee (DISHA) was formed in 2016. The goal was to coordinate between the Central, State and Local Panchayat Governments for successful and timely implementation of key schemes (such as the National Rural Livelihoods Mission, Pradhan Mantri Awaas Yojana and Swachh Bharat Mission). To monitor the schemes and make data-driven implementation decisions, stakeholders needed to get meaningful insights about the schemes. This required integrating the different systems containing the scheme data.
Last year, we partnered with the Ministry of Rural Development (MoRD) and National Informatics Centre (NIC) to create the DISHA dashboard, which was launched by the Prime Minister in October. The DISHA Dashboard helps Members of Parliament (MPs), Members of Legislative Assembly (MLAs) and District Officials track the performance of flagship schemes of different central ministries in their respective districts and constituencies.
Back in October 2017, the dashboard had data for 6 schemes, and it was updated in August 2018 to show data for a total of 22 schemes. In its final phase, the dashboard will unify data from 42 flagship schemes to help stakeholders find the answer to life, universe and everything. For the first time, data from 20 ministries will break silos to come together in one place, bringing accountability to a government budget of over Rs. 2 lakh crores!
The DISHA meetings are held once every quarter, where the committee members meet to ensure that all schemes are being implemented in accordance with the guidelines, look into irregularities with respect to implementation and closely review the flow of allocated funds. Workflows, like the one showed above, have automated the flow of data from scheme databases to the DISHA Dashboard, updating the dashboard regularly with the most recent data for a scheme. This is useful for the committee members since they can plan for the meeting agenda by checking each scheme’s performance and identifying priorities and gap areas.
Watch the Prime Minister speak about how he uses the DISHA dashboard to monitor the progress of Pradhan Mantri Awas Yojna here.
Going towards better public technology
Data extraction is a piece of a larger puzzle called data integration (getting the data you want to a single place, from different systems, the way you want it), which people have been working on since the early 1980s. Integrating different data systems can be quite complex due to the systems being heterogeneous; this means they can differ in the way they are implemented, how data is stored within them and how they interact with other systems, making them silos of information.
To successfully extract data from another system, people on both ends of the transaction first need to agree upon a schema for how the data will be shared. As we found, this can be the most time-consuming part of a project, given how heterogeneous different data systems can be. Even though we have successfully integrated 22 data sources together so far, the time we spent on getting the data in the right format, with the variables we needed for each scheme, would’ve been saved if there was a standard for storing and sharing data across all ministries.
In his article “Bringing Wall Street and the US Army to bear on public service delivery”, Varun Adibhatla of ARGO Labs talks about ‘Information Exchange protocols’. He calls it jargon for, being able to share standardized data or speak a common language at some considerable scale. He further explains here that, in the 1990s, Wall Street financial institutions got together and agreed to speak in a common transactional language. This led to the creation of the FIX protocol, which let them share data quickly. He mentions that data standards like the FIX protocol are not unique to Wall Street, but exist in almost every sphere of trade and commerce.
‘A small team of purpose-driven public technologists, leveraging advances in low-cost device, data and decision-making and the right kind of support is all it takes to build and maintain public, digital infrastructures.’ — Varun Adibhatla in “Bringing Wall Street and the US Army to bear on public service delivery.”
As we move towards a Digital India, we need a fundamental shift from the Excel-for-everything mindset and how today’s public technology is set up. We need a standardized data infrastructure across public services that will help ministries and departments share data with each other quickly, and with the public. A new generation of public servants with Silicon Valley–grade technical chops need to be trained and hired. There’s already a Chief Economic Advisor to the government and a Chief Financial Officer for the RBI. It’s high time a Chief Data Officer is appointed for India!